本文共 742 字,大约阅读时间需要 2 分钟。
为了将品牌重塑为一个平台型的公司,MapR正扩展其聚合数据平台,以创建一个云级别的数据存储平台,来管理文件、对象和容器。其最新发布的MapR-XD支持从边缘到数据中心和多个云环境的任何数据类型。
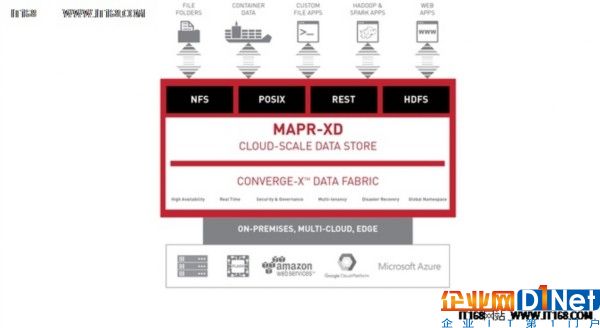
“我们从客户口中了解到,他们正在寻找一个可伸缩的存储平台或数据管理平台,要能做很多东西,包括支持多站点、数据中心和处于边缘的云在一个全局命名空间中。” MapR行业解决方案的高级主管,Bill Peterson说。
MapR-XD解决方案可用于闪存和磁盘。根据彼得森的说法,该公司决定不对块存储予以支持,因为块存储没有元数据,无法对其进行分析。他表示:“我们真正想做的是专注于非结构化数据,帮助企业创建这种云计算数据结构,让他们能够对数据进行分析。”
作为公告的一部分,MapR还将其云级别的数据存储、分析和机器学习引擎、操作数据库和事件数据流重新命名为MapR converx数据结构,以提供高可用性、实时、统一的安全性,多租户和灾难恢复。
MapR-XD的特性包括:文件、对象和容器支持;全局exabyte规模;云级别的可靠性;使用flash的速度;对容器化应用程序的有状态的持久化;利用多个基础设施的灵活性;物联网的边缘处理和存储能力;以及可扩展的体系结构。
根据彼得森的说法,这些特性允许XD提供完全成本的所有权,消除筒仓、数据感知,并且能够在任何地方部署和执行。
“随着应用程序变得更加智能,而且实时利用更多的数据,在分析和操作的使用中,出现了对数据处理的新方法,”451 research的数据平台和分析研究主管Matt Aslett说。“MapR-XD被设计用来消除数据筒仓,并支持新的用例,是因为它们需要从边缘、数据中心到云计算进行数据处理。”
本文转自d1net(转载)